英伟达不仅有NVLink、InfiniBand,还有以太网Spectrum-X方案
传统数据中心南北向网络和典型的AI东西向网络有非常明显的特征差异,总体来说AI属于分布式紧耦合业务的类型,对低延迟抖动、无阻塞以及可预期的网络性能有着明确的诉求。
AI训练的本质就是一堆GPU卡不停的“算算数”(梯度计算),为了让成百上千的GPU卡协同工作,就有了数量并行(把训练的数据拆分成不同的子集分给不同GPU计算)、模型并行(把模型中神经网络的不同层拆分给不同GPU计算)、张量并行(把同一层张量拆分成不同小块给不同GPU计算),不管是那种方式都需要GPU间的大量数据交互,对通信网络的需求就是:高速、低延迟、无拥塞、无丢包。
英伟达在AI网络通信方案方面的策略是All In:“小孩子才做选择,你要啥我有啥!”,不但有NVLink网络(主要应用于服务器内部的GPU通信以及小规模跨服务器节点间的数据传输)、InfiniBand网络(适用于中小规模且对价格不敏感的客户群体),还有推出了基于ROCE无损以太网的Spectrum X平台方案。

NVIDIA® Spectrum™-X 网络平台是第一个专为提高Ethernet-based AI云的性能和效率而设计的以太网平台。在类似LLM的大规模AI工作负载中,提升了1.7倍AI性能、能效,以及保证在多租户环境中的一致、可预测性。Spectrum-X基于Spectrum-4以太网交换机与NVIDIA BlueField®-3 DPU网卡构建,针对AI工作负载进行了端到端优化。
Spectrum-4以太网交换机
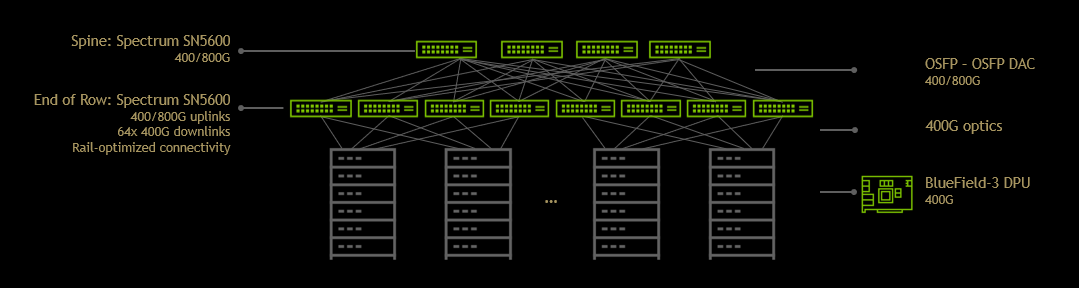
NVIDIA Spectrum-4 以太网交换机基于其自研的 51.2Tbps 的 Spectrum-4 ASIC 而构建,支持单个2U交换机中最多128个400G以太网端口或64个OSFP 800G接口,两级CLOS组网支持8K GPU节点。Spectrum-4 ASIC 采用了112G SerDes通道,Spectrum-X方案从交换机到DPU到GPU都采用了相同的SerDes技术,可以降低网络功耗,提高网络效率。
BlueField-3 DPU网卡:
NVIDIA BlueField-3 DPU是第三代数据中心基础设施芯片,使组织能够构建从云到核心数据中心到边缘的软件定义的、硬件加速的IT基础设施。通过400Gb/s以太网网络连接,BlueField-3 DPU可以卸载、加速和隔离软件定义的网络、存储、安全和管理功能,从而显著提高数据中心的性能、效率和安全性。BlueField-3为由Spectrum-X驱动的云AI数据中心中的南北和东西流量,提供多租户、安全性能力。
RoCE自适应路由解决AI网络中低熵(流负载不均衡)问题
传统以太网ECMP流量负载均衡机制,由于不同流量的大小不一样,大象流(如:几个G的大文件),“老鼠流”(如:几K到几M的小流量)都按照哈希算法进行调度时,会导致网络整体利用率很低(通常达不达60%),业内解决办法就是把逐流负载改成逐包负载(包喷洒),但逐包负载的难题是流乱序问题,同一条流的不同数据包被负载到不同链路上转发,会出现数据包乱序的情况,需要有相应机制处理对错序的数据包进行重新排序。
RoCE 自适应路由是一种细粒度的负载均衡技术。它动态地重新路由 RDMA 数据以避免拥塞,并提供最佳负载均衡以实现最高的有效数据带宽。
它是一种端到端功能,包括 Spectrum-4 交换机和 BlueField-3 DPU 。Spectrum-4 交换机负责为每个数据包选择最不拥塞的端口进行数据传输。由于同一流的不同数据包通过网络的不同路径来传输,它们可能会无序到达目的地。BlueField-3 在 RoCE 传输层转换任何无序数据,透明地将有序数据传递给应用程序。
Spectrum-4 根据出口队列负载评估拥塞,确保所有端口都很好地均衡。对于每个网络数据包,交换机都会在其出口队列中选择负载最小的端口。Spectrum-4 还接收来自相邻交换机的状态通知,这会影响路由决策。所评估的队列与服务质量级别相匹配。
NVIDIA 是在DPU网卡侧处理乱序的数据包,业内处理数据包乱序到达的思路还有“信元”+交换机侧缓存排序的DDC方案、对普通以太网数据包进行编号(虚拟容器化)+交换机侧排序的智能调度方案,如果大家感兴趣可以直接点关键词看我的历史文章。
NVIDIA RoCE拥塞控制
INCAST引起的拥塞问题不是逐包负载均衡能解决的,这种拥塞的主要原因被称为多对一拥塞,即存在多个数据发送方和单一数据接收方。必须通过拥塞控制来解决,NVIDIA采用端网协同的拥塞控制机制来减少网络拥塞问题。
这种拥塞不能使用自适应路由来解决,并且实际上需要对每个端点的数据流进行计量。拥塞控制是一种端到端的技术,Spectrum-4 交换机提供代表实时拥塞数据的网络遥测信息。这些遥测信息由 BlueField DPU 处理,后者管理和控制数据发送方的数据注入速率,从而实现网络共享的最大效率。
如果没有拥塞控制,多对一的场景将导致网络背压和拥塞扩散,甚至出现丢包,从而极大地降低网络和应用程序的性能。
在拥塞控制过程中,BlueField-3 DPU 执行拥塞控制算法。它们以微秒的反应延迟每秒处理数百万个拥塞控制事件,并应用细粒度的速率决策。
Spectrum-4 交换机带内遥测既包含用于准确拥塞估计的排队信息,也包含用于快速恢复的端口利用率指示。NVIDIA RoCE 拥塞控制通过使遥测数据绕过拥塞流排队延迟,同时仍然提供准确和并发的遥测,从而显著改善了拥塞发现和反应时间。
RoCE 性能隔离
人工智能超大规模和云基础设施需要支持越来越多的用户(租户)和并行应用程序或工作流。这些用户和应用程序无意中竞争基础设施的共享资源(如网络),因此可能会影响性能。
NVIDIA Spectrum-X 平台包括一些机制,当它们结合在一起时,可以提供性能隔离。它确保一个工作负载不会影响另一个工作负荷的性能。这些机制确保任何工作负载都不会造成网络拥塞,从而影响另一个工作负载的数据移动。性能隔离机制包括服务质量隔离、用于数据路径扩展的 RoCE 自适应路由和 RoCE 拥塞控制。
NVIDIA Spectrum-X 平台具有软件和硬件的紧密集成功能,能够更深入地了解人工智能工作负载和流量模式。这样的基础设施提供了使用专用以太网 AI 集群进行大型工作负载测试的能力。通过利用来自 Spectrum 以太网交换机和 BlueField-3 DPU 的遥测技术,NVIDIA NetQ 可以主动检测网络问题并更快地解决网络问题,以优化网络容量的使用。
NVIDIA NetQ 网络验证和 ASIC 监控工具集提供了对网络健康状况和行为的可见性。NetQ 流遥测分析显示了数据流在穿越网络时所采用的路径,从而提供网络延迟和性能洞察