Over the past decade, Software-Defined Networking (SDN) emerged as a game-changer, becoming the go-to standard for data center networking. Its rise aligned perfectly with the needs of cloud-scale operations, offering substantial gains in efficiency. SDN delivered two key benefits: enhanced control and greater flexibility. By separating network control from data forwarding, it allowed operators to program the network dynamically while abstracting the underlying hardware from applications and services. This programmability sharpened control, and the abstraction unlocked flexible implementation, driving faster feature rollouts and predictive management in data centers.
Meanwhile, Remote Direct Memory Access (RDMA) networks carved out a niche in smaller-scale deployments, primarily in storage and high-performance computing (HPC). These setups were modest compared to the sprawling infrastructures where SDN thrived. Early attempts to scale RDMA for cloud environments—seen in pioneers like Microsoft Azure and Amazon Web Services (AWS)—hit roadblocks tied to control and flexibility, though each tackled the hurdles differently, as we’ll explore later.
Now, in the current decade, the explosive growth of AI—particularly GPU-driven backend or scale-out networking—has thrust RDMA into the spotlight. The surge in Generative AI (GenAI) and Large Language Models (LLMs) has unleashed new demands: higher performance, scalability, and unique traffic patterns. LLM training, for instance, generates sporadic data bursts with low entropy and intense network use, maxing out modern RDMA NICs at 400 Gbps. These patterns throw off traditional Equal-Cost Multi-Path (ECMP) load balancing, a staple of SDN-based data centers, pushing operators to rethink their designs.
The AI boom has sparked an unprecedented race, with data center operators sidelining the control and flexibility they once prized. Today’s RDMA deployments favor tightly integrated, vendor-specific rack designs over decoupled systems, prioritizing speed-to-market over adaptability. While abstraction exists in the AI stack, the breakneck pace of deployment leaves little room to ensure compatibility across diverse RDMA NICs.
This shift has split data center networking into two realms: legacy and modern. Front-end networking—covering storage and general compute—remains SDN’s domain, preserving its value. Backend GPU networking for AI, however, is a new frontier where control and flexibility take a backseat to the GenAI arms race. SDN has little presence here. The network landscape has diverged.
Alibaba’s production data underscores the stakes: a fault in LLM training costs 20 times more than a glitch in general cloud computing. As GPU clusters grow to rival the scale of traditional cloud setups, the operational efficiencies honed in SDN-driven systems will likely reclaim their relevance. The hunger for control and flexibility isn’t fading—it’s enduring. Innovations decoupling control and abstracting infrastructure, already emerging, signal a future where RDMA catches up.
Why RDMA Networks Need Control and Flexibility
As GPU clusters balloon in size, the demand for control and flexibility in RDMA-based AI networks will intensify. The next wave of GenAI—think multi-trillion-parameter multimodal transformers trained on vast video, image, audio, and text datasets—will amplify this need. To understand where this is heading, let’s revisit how cloud giants like Microsoft, AWS, Google, Meta, and Alibaba scaled RDMA to clusters of up to 32,000 GPUs. The next leap? Clusters exceeding 100,000 GPUs.
Microsoft Azure’s RDMA Journey
Microsoft pioneered RoCEv2 (RDMA over Converged Ethernet) for reliable, latency-sensitive storage and HPC services. To scale it for broader intra-data-center use, Azure enhanced its infrastructure with new features (see Table 1).
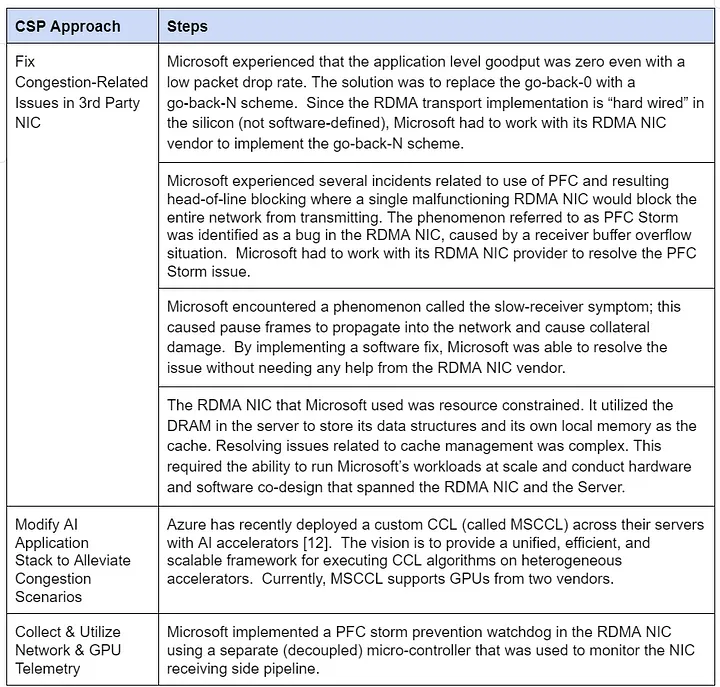
Table 1: Microsoft Azure’s RDMA Scaling Approach
- Control Assessment: Medium. The RDMA transport relies on a single vendor’s hardware, tethering feature updates to the NIC provider’s timeline. No custom switch features are needed, though.
- Flexibility Assessment: Medium. Azure uses one RDMA NIC vendor but pairs it with standard switches and designs workable across varied data centers. Tools like MSCCL enable GPU vendor flexibility, though it’s unclear if this extends to NIC procurement.
Note: Azure’s control may grow with programmable NICs from its Fungible acquisition and the MAIA accelerator’s custom RoCE-like protocol, though programmability remains uncertain.
AWS’s RDMA Strategy
AWS faced similar scaling hurdles but took a bold, ground-up approach (see Table 2). To ensure low-latency HPC and AI performance, it built its own RDMA solution.
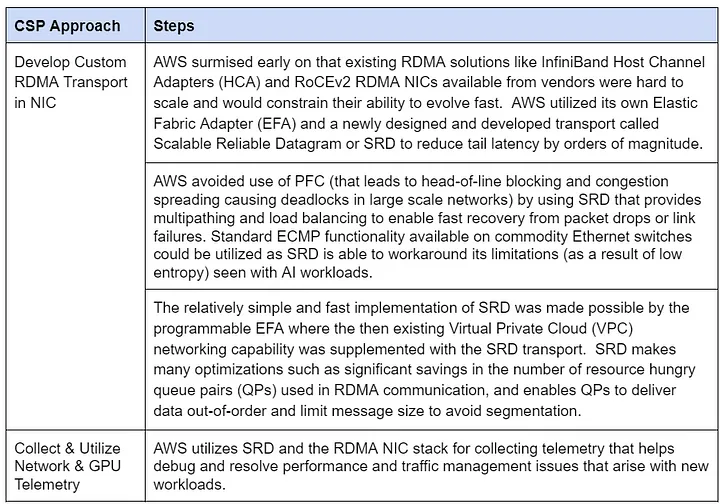
Table 2: AWS’s RDMA Scaling Approach
- Control Assessment: High. AWS’s programmable RDMA NIC lets it innovate independently of NIC or switch vendors.
- Flexibility Assessment: High. Free of vendor ties, AWS uses commodity switches and adaptable designs across its data centers.
Google’s RDMA Path
Google’s Falcon protocol, donated to the Open Compute Project in 2023, powers its RDMA-capable Infrastructure Processing Unit (IPU) NIC (see Table 3). It blends Microsoft’s vendor reliance with AWS’s custom transport flair.
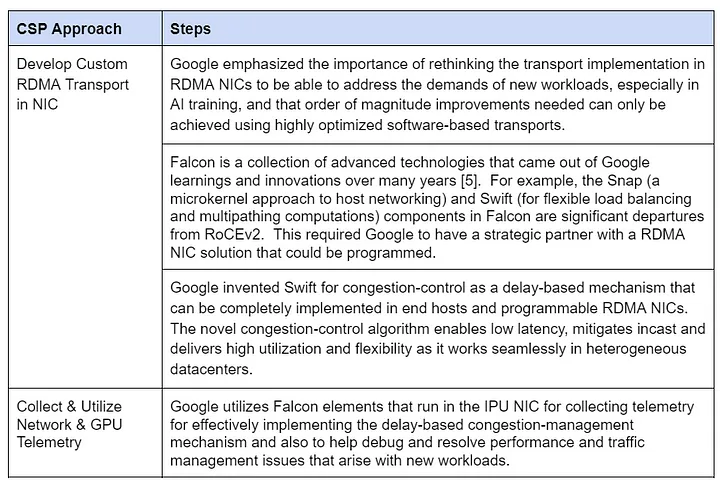
Table 3: Google’s RDMA Scaling Approach
- Control Assessment: Medium. Programmable cores let Google tweak congestion control swiftly, though hardware upgrades depend on the NIC vendor.
- Flexibility Assessment: High. Google controls core RDMA features and uses standard switches and designs across its data centers.
Meta’s RDMA Approach
Meta tailors its RDMA network to its workloads, optimizing infrastructure over transport innovation (see Table 4).
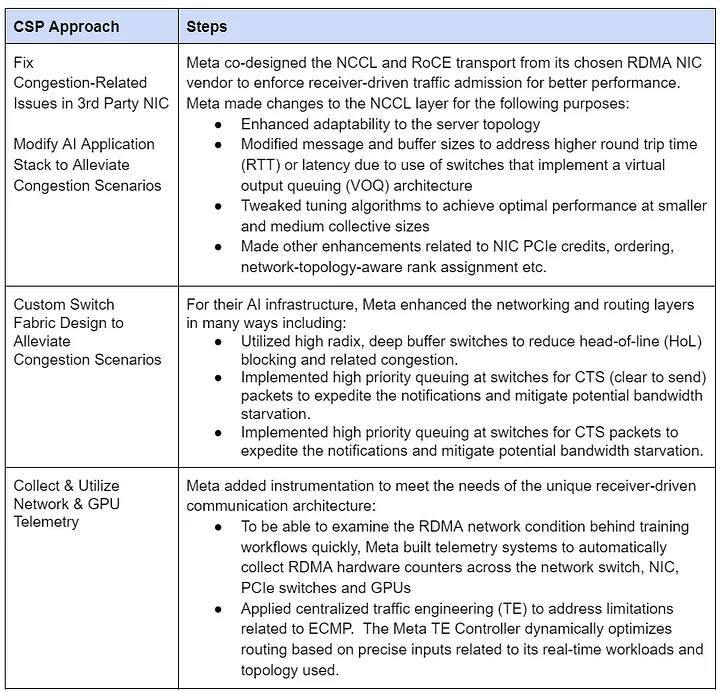
Table 4: Meta’s RDMA Scaling Approach
- Control Assessment: Low. A single NIC vendor gates updates, and specialized deep-buffered switches tie Meta to switch vendors.
- Flexibility Assessment: Low. Congestion solutions and telemetry hinge on vendor-specific RoCE and NCCL, with a unique switch fabric limiting adaptability.
Alibaba’s RDMA Design
Alibaba’s High-Performance Networking (HPN) architecture, used for LLM training, tweaks application and switch layers rather than RDMA transport (see Table 5).

Table 5: Alibaba’s RDMA Scaling Approach
- Control Assessment: Medium. NIC vendor hardware limits updates, but standard switches reduce reliance on custom features.
- Flexibility Assessment: Low. Tied to vendor RoCE and NCCL, Alibaba’s custom switch fabric diverges from its broader designs.
What’s Next: Trends and Impact
Table 6 sums up control and flexibility across these CSPs. AWS and Google lead, Meta and Alibaba lag, and Microsoft sits in between.
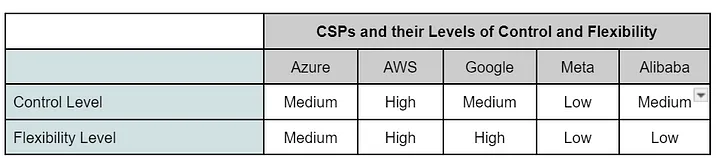
Table 6: Control and Flexibility by CSP
As clusters scale to hundreds of thousands of GPUs, new challenges loom:
- Power constraints pushing smaller, distant clusters with higher latency and packet loss.
- Demand for resilience to boost model FLOPS utilization and ROI.
- Bandwidth needs for next-gen GPUs.
- Lower latency across vast GPU sets for GenAI collective operations.
Custom transports like Microsoft’s MAIA RoCE and Tesla’s TTPoE hint at a trend: more CSPs building accelerators may follow suit, amplifying the need for control and flexibility in RDMA.
Innovating Software-Defined RDMA
To restore control and flexibility, RDMA must embrace SDN’s hallmarks: decoupling and abstraction. Enfabrica’s multi-GPU SuperNIC offers a glimpse of this future. (For details, see Enfabrica’s materials [11].) Here’s the gist:
Decoupling
The SuperNIC splits RDMA’s data and control paths physically while linking them logically. A high-throughput, zero-copy data path feeds endpoints like GPU HBM, while an independent control path—running on a CPU—handles flexible protocols (e.g., RoCEv2, AWS SRD, Google Falcon). This lets operators tweak semantics like retransmissions without touching the data path.
Abstraction
By abstracting the split, the control path (software on a CPU) evolves independently of the hardware data path. Operators can update control logic at their own pace, while hardware upgrades (e.g., speed boosts) don’t disrupt software. APIs stay compatible with frameworks like xCCL and PyTorch, easing integration.
![]()
Figure 1: SuperNIC Transport Flexibility shows dual stacks—RoCEv2 and a new transport—sharing the same data path, with only driver and RDMA core layers adjusted.
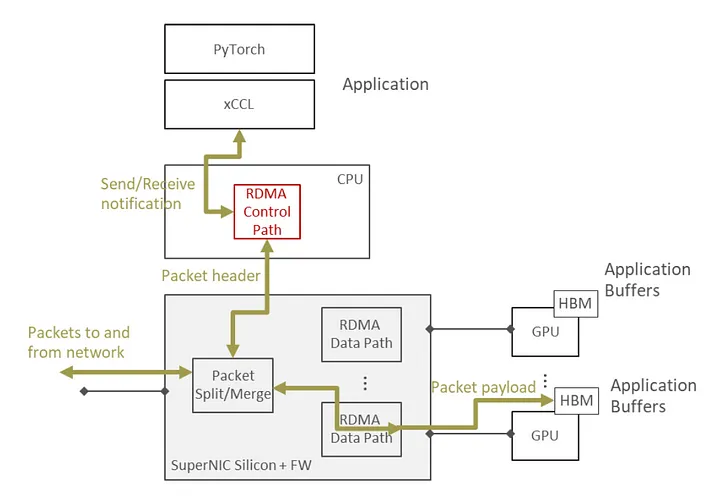
Figure 2: Control/Data Split illustrates the SuperNIC merging headers and data for zero-copy GPU transfers, with a software control stack managing transport and applications.
Boosting Control and Flexibility in AI Clusters
This SuperNIC restores critical capabilities as clusters scale:
- Flexible bandwidth allocation based on workload and topology.
- Simplified switch designs.
- Seamless app support for faster deployment.
- Wider visibility for congestion detection and telemetry.
- Operator-controlled congestion fixes.
- Global addressing optimizing PCIe and Ethernet traffic.
- Dynamic failure response and custom metrics for resilience.
Wrapping Up
SDN fueled cloud-scale efficiency, while RDMA grew in smaller HPC and storage niches. AI’s rise has scaled RDMA to 32,000-GPU clusters, with some CSPs clinging to SDN’s benefits and others trading them for speed. As GenAI pushes clusters to hundreds of thousands of GPUs, control and flexibility will reclaim their throne. Innovations like the SuperNIC promise to bring SDN-like efficiencies to RDMA, powering the AI networks of tomorrow.